
BY ALI RAZA
Machine learning is the engine which drives Face ID, filtering spam emails and recommending
videos for your ‘for you page’. Over the last few years, advancements in AI through apps like
ChatGPT have put a lot of eyes onto machine learning. A subset of this is ‘Computer vision’
which is the machine learning driven process of a computer being able to recognise and
process images for specific purposes. Computer vision can be used in a variety of helpful ways
and you could even use it to make your own apps with nothing but an internet connection. So
while machine driving can aid in tasks such as self-driving cars and Face ID, how can we use it
to aid in the battle against one of humanity’s biggest blights: Cancer?
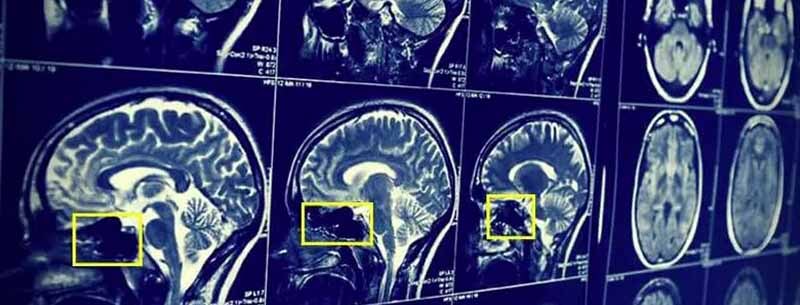
The accurate diagnosis is crucial for correctly treating any disease, let alone cancer. Doctors
assess the images produced from scans such as MRIs to look for tumours, they can do this
because they have a deep knowledge of anatomy and how tumours can appear with imaging.
With this information they can formulate a treatment plan for the patient to ensure they receive
the fastest and safest recovery. Doctors are humans though, they can not constantly study the
results of medical imaging 24/7, they can make mistakes and also have many other
responsibilities. This is where machine learning comes in. Using a machine learning driven
approach, we can create an algorithm that’s sole purpose is to scan through imaging data 24/7.
Not only does this save the time of the doctor, but is also far more efficient and accurate as the
algorithm can not fatigue or has to take breaks. But how is a computer able to see and process
images?
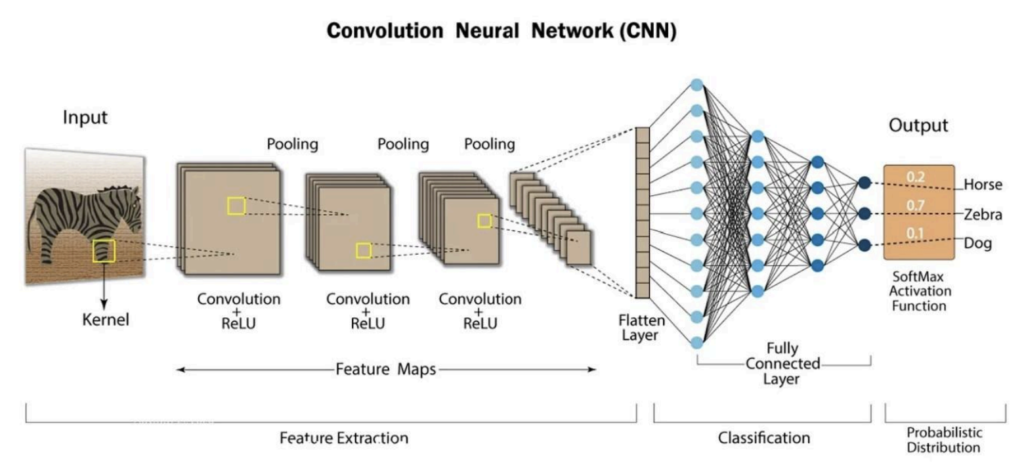
A computer uses an AI network called a convolutional neural network (CNN) to do this. A CNN
works by segmenting an image into grids of numbers; these numbers can represent things such
as the brightness of a pixel in a black and white image from 0 to 255. A coloured image would
have 3 grids, representing red, green and blue. After breaking the images into grids, the CNN
will look for simple patterns like edges and lines, still in segments. You can imagine it by thinking
of a small window sliding over an image and taking note of lines and edges to get a gist of the
pattern, this is called the convolutional layer. After finding patterns, the CNN makes the image
smaller while keeping the important details to make it easier to process. CNNs do not know
what to look for, they learn from examples. If you keep feeding a CNN images of cats for
example, it will adjust its layers to recognise features commonly found in cats such as pointy
ears or whiskers. You can ‘train’ a CNN by repeatedly feeding images that you want it to be able
to detect and it will adjust its layers to become better at detecting this thing. After the CNN has
fully processed an image, it will give its final verdict on what the image is; for example, if I train it
on images of healthy and cancerous MRI scans of the brain, when I input a new MRI scan, it will
be able to predict if it is has a tumour or not. Starting to see how this can help with cancer
treatment?
If we use a CNN and feed it heaps of data of medical imaging that has healthy and cancerous
images, we can use it to accurately diagnose if a patient has cancer. If it is made properly, it is
more accurate and more efficient than the most specialised doctor. While this sounds very
advanced, machine learning has become very accessible in recent years and you can do this
yourself as long as you have an internet connection. I’ve made a basic brain tumour detector
that uses a premade machine learning model called ResNet. I can input images from MRI scans
of the brain and it can tell me if the images are cancerous or healthy. All I did to do this was find
an online dataset of MRI scans, train my premade model on the dataset and that’s it! After
training on a few hundred images, this was the accuracy I achieved on a set of data that was
used to test how well the model performs.
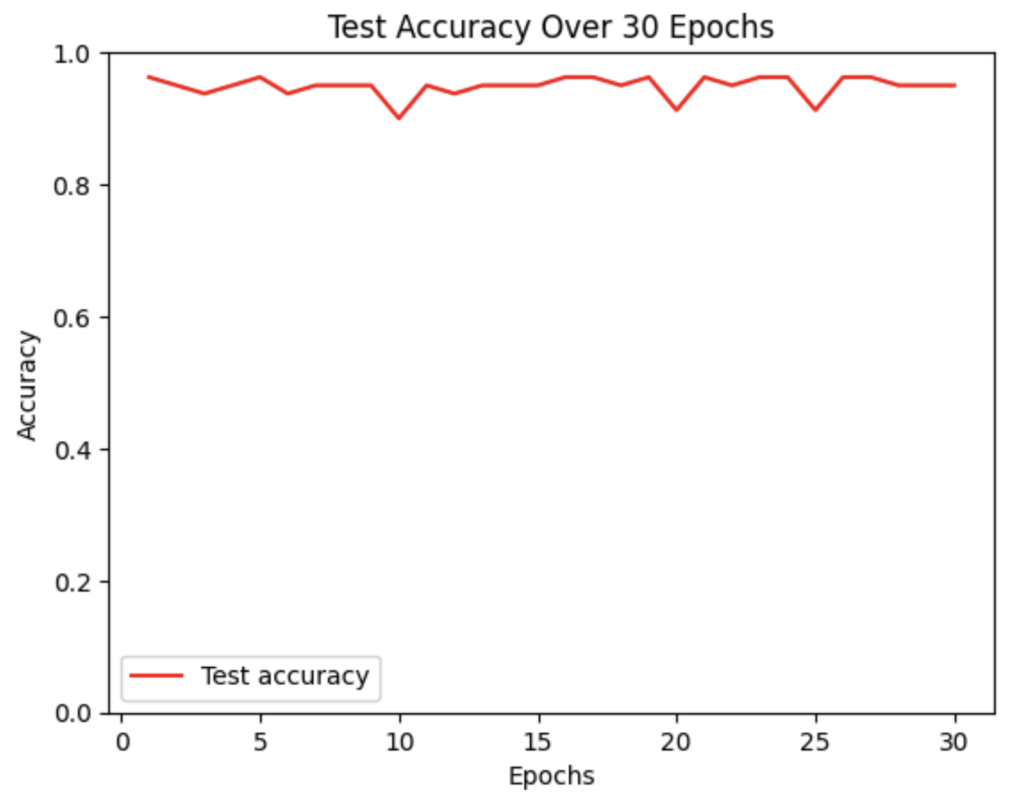
The y-axis represents the accuracy of the model on each batch of data it was given, the x-axis
represents epochs. An epoch refers to a round of data inputted. In this instance, I inputted 30
rounds of data and achieved around 0.9+ accuracy for each epoch, showing my model was
highly accurate. All of this requires little skill and could be achieved by following a YouTube
tutorial, which begs the question: Why is this not used in all hospitals everywhere?
While using computer vision for cancer diagnosis could be revolutionary, especially in
economically deprived areas with a lack of specialists, they are far harder to make than the one
I made if they need to be used in a clinical setting. My model only used around 800 or so
images, a real life model for cancer detection would need hundreds of thousands and potentially
millions. Sourcing this amount of data becomes challenging, especially for rarer types of
cancers. A proposed solution for this is using AI to generate more images that can be used for
training, but this could lead to accuracy issues. A huge amount of computational power is
required to train a CNN. I was able to train mine using an online hosting service called Google
Collab. Google owns the GPUs which I trained my model on and I ‘borrowed’ them temporarily.
For a commercial use, this would likely not be enough and a company would need their own
GPUs that can be very expensive. I used a premade model and trained it on data, this made the
whole process much easier. Making a model from scratch requires much more time and
technical knowledge of advanced maths and computer science, if a model was being used for
something like cancer diagnosis, it can not afford having a low accuracy so it would likely make
a new model specifically for this purpose. Despite all these challenges, computer vision holds
immense potential for revolutionising the way we treat cancer and other complex diseases and
this will only improve as technology advances.