

BY HASAN MUSTAFA
Machine learning is a transformative force in AI that has revolutionized industries and reshaped the world. It is defined as the field of study that allows systems to learn and recognize patterns without being explicitly programmed. These systems can imitate intelligent human behavior and perform complex tasks using nuanced contextual understanding such as identifying text written in natural language, understanding visual scenes, etc.
There are three fundamental categories of machine learning: supervised, unsupervised, and reinforcement learning. Supervised learning is the most elementary of the three, in which machines are trained on a pre-labelled dataset, while unsupervised learning utilizes unlabeled data. Reinforcement learning occurs when the system receives feedback on its performance to adjust and improve its performance in the long run. In this article, we will further delve into these categories and their applications in machine learning.
1. Supervised learning
Supervised principles revolve around learning a mapping between a set of inputs x1,x2,…and corresponding output variables y1,y2.. and applying this mapping to predict the outputs of unseen data through pattern recognition and analysis. It is mainly used for prediction and classification purposes when given a set of new data, based on its analysis and findings using the training data.

Supervised machine learning algorithms require external assistance and use labeled training data for a specific use case, which the system uses for analysis. Its performance is then assessed on how accurately it can identify or deduce the correct output on an unlabelled test dataset. The model is tuned based on the results thus improving it. Once the model reaches a reasonable accuracy it can then be deployed for production in real-world scenarios.
1.1 Decision Trees
Decision trees are one of the techniques used to implement supervised learning. They are statistical algorithms that are used for general-purpose prediction and classification in a diverse range of fields.

Decision trees recursively split the entire dataset into subsets on the values of specific attributes creating nodes in the tree. This process continues until the desired level of accuracy is reached, or when the tree becomes too complex. This resultant decision tree can be used to make predictions for new data points by mapping pathways from the root to the appropriate leaf node.
For example, a bank may use a decision tree to determine the likelihood that a loanee would default on their loan, based on various factors such as credit score, monthly income, and current employment status. Simple scenarios would include a loan applicant with an 800+ credit score and substantial income, who might have direct approval. However, more complex cases such as applicants who change jobs often, or a history of late payments could result in a deeper analysis within the decision tree to reach an efficient course of action.
1.2 Naives Bayes

Naives Bayes is a statistical classification technique that is derived from Bayes’ probability theory, which is used for text classification such as sentimental analysis, classifying articles and spam filtration.
Assumptions made by the algorithm:
1. Predictors are conditionally independent
2. Assumes that all features contribute equally to the resultant outcome
2. Unsupervised Learning
In unsupervised learning, the machine simply receives inputs x1, x2, . . ., but obtains neither corresponding y1,y2.. outputs nor feedback from an external environment. Instead the algorithm independently explores and discovers key structures in the data, and when it is presented with new data, uses the previously learned features to recognize the class of the given data. It is mainly used for clustering and feature reduction.
2.1 K-Means Clustering
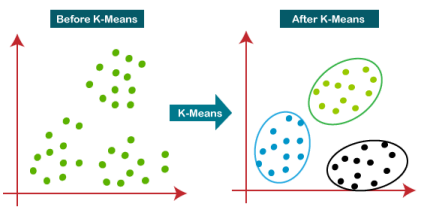
K-means is considered an exclusive clustering method which entails that any given datapoint can only exist in any one cluster. It works by partitioning the dataset into similar groups based on their centroids. A centroid/cluster center is the mean or median of all the data points in a given cluster, the method used to calculate the centroid is dependent on the characteristics of the data. K-Means is mainly used in data science for market segmentation, document clustering, image segmentation, and image compression.
2.2 Principal Component Analysis
Principal component analysis (PCA) is used for the preprocessing of data for use in machine learning algorithms. PCA works by reducing the complexity of the model through reducing the number of dimensions in a given data set, which is useful as each new dimension/feature will negatively affect the performance of the model. It can do this by transforming potentially correlated variables into principal components which are a smaller set of variables.
3. Reinforcement Learning

Unlike supervised and unsupervised learning, reinforcement learning isn’t given a set of inputs. It instead occurs when a machine interacts with its environments producing actions a1,a2,a3… which can impact the state of the environment. These actions are then met with feedback, usually receiving scalar rewards or punishments with r1,r2, r3…, which are used to finetune the model and maximize its performance/accuracy.
3.1 Monte Carlo Methods
They are a wide category of computational algorithms that utilize repeated random sampling to obtain the probability of a range of results occurring. These algorithms use randomness to solve problems which are deterministic in principle. It’s used across three main categories of problem classes: Numerical integration, optimization, and making drawings from a probability distribution.
3.2 Q-Learning
Q-learning is a model-free reinforcement algorithm, which means they learn through the consequences of their actions without the use of a rewarding mechanism or transition. The ‘Q’ in Q-learning stands for quality, meaning that the action with the highest Q-value is the action that it sees to be the most optimal, and usually chooses these actions most frequently. Essentially Q-learning works by creating a Q-table where it assigns a Q-value to each possible action in a given scenario, it then chooses and performs an action, evaluates and measures the reward then updates the Q-table.
4. Applications of Machine Learning
4.1 Cyber Security and Threat Intelligence
Cybersecurity is a rapidly growing industry in the age of modern computing and revolves around protecting data, systems, and networks from malicious online attacks. Machine learning allows cybersecurity technologies to analyze data to identify patterns, detect malware in encrypted traffic, and quarantine them, which plays a crucial role in keeping people safe online. For example, clustering techniques can be used to identify policy violations or cyber anomalies.
4.2 Healthcare and COVID-19 Pandemic
Machine learning can be used to solve a variety of problems in healthcare, both diagnostic and prognostic. Some examples include detecting irregularities in patient data, optimizing patient management, and predicting disease. Machine learning also played a significant role during the COVID-19 pandemic as it allowed authorities to forecast where and when the virus would spread and take the necessary steps in advance. It also helps classify patients at high risk, and their mortality rate among other things. Overall, machine learning has played a vital role in advancing healthcare and helping medical authorities make well-informed decisions in various situations.
4.3 Sustainable agriculture
Machine learning can play an important role in developing sustainable agricultural practices and improving agricultural productivity. These technologies can be applied at various phases of sustainable agriculture to predict crop yield, soil properties, irrigation requirements, and weather prediction, in order to maximize the crop yield while minimizing the negative impact on the environment. This would help solve food shortages while combating climate change.
Conclusion
Machine learning has played an indispensable role across fields like healthcare, cybersecurity, and agriculture by leveraging various techniques from supervised, unsupervised, and reinforcement learning. The ability of these systems to process data, carry out tasks, identify patterns, and learn from mistakes has created a wide range of applications.
Reference list
Brown, S. (2021). Machine learning, explained. [online] MIT Sloan. Available at: https://mitsloan.mit.edu/ideas-made-to-matter/machine-learning-explained.
CunninghamP. ́draig, Cord, M. and Delany, S. (2008). Supervised Learning. In: CunninghamP. ́draig and M. Cord, eds., Machine Learning Techniques for Multimedia. Springer.
de Ville, B. (2013). Decision trees. Wiley Interdisciplinary Reviews: Computational Statistics, 5(6), pp.448–455. doi:https://doi.org/10.1002/wics.1278.
Ghahramani, Z. (n.d.). Unsupervised Learning Guide. Retrieved from http://datajobstest.com/data-science-repo/Unsupervised-Learning-Guide-%5BZoubin-Ghahramani%5D.pdf
IBM (2023). What is principal component analysis? | IBM. [online] www.ibm.com. Available at: https://www.ibm.com/topics/principal-component-analysis.
Kavlakoglu, E. and Winland, V. (2024). What is k-means clustering? | IBM. [online] www.ibm.com. Available at: https://www.ibm.com/topics/k-means-clustering.
Mahesh, B. (2018). Machine Learning Algorithms -A Review. International Journal of Science and Research (IJSR) ResearchGate Impact Factor, [online] 9(1). doi:https://doi.org/10.21275/ART20203995.Sarker, I.H. (2021). Machine Learning: Algorithms, Real-World Applications and Research Directions. SN Computer Science, 2(3), pp.1–21. doi:https://doi.org/10.1007/s42979-021-00592-x.